
Hello, I am writing this quick article to:
- present a dataset that I built during the past weeks
- get an overview of some features of nltk
Who are you ?
Doctor Who is a British TV show , a science fiction one that starting in 1963 produced by the BBC , the programme telling the story of the Doctor an alien (with a human form) that is travelling on the universe in his time machine / spaceship called the Tardis (a police box).
During this travel in space and time, the Doctor is followed by companions from Earth because he has some preference for the planet Earth (that’s very convenient isn’t it). The Doctor is very smart, funny etc but the two main features of the characters (that are coming from his alien race the time lord) are :
- He is kind of immortal
- When he dies he is coming back to life in a new human form (very useful for the end of contract). Each regeneration keeps the memory of the previous form but he has a new look and a new comportment. But this regeneration process is limited in number of iterations
In terms of show , there is two phases that can be defined (that’s my term so please doctor who fans don’t exterminate me):
- The classic area from 1963 to 1989
- The modern area from 2005 to now
From my part I discovered Doctor Who around 2010 , so I am more a modern area guy and I am not very familiar with the classic area but what I like with the modern area , it is that they are reimporting the lore of the classic area and make a refresh and an update (like redesign the enemy of the doctor for example).
Anyway, this show is a diamond of the british pop culture from the reference , to the actor and if you like science fiction is definitely worth watching it.
So now let’s dive into the data of this project.
Presentation of the dataset
So let’s be honest this dataset has been inspired by this other dataset focused on the Simpsons TV show.
I scraped data from different websites:
- The scripts of the episodes are coming from the website chakoteya where it can be found for each episode all the dialogues etc
- The rating of each episode of the modern area are coming from IMDB
- The information on the episode are coming from the doctor who guide and contains details on the episode, the distribution of the cast or the crew.
These dataset is giving different details on the show and can be useful to determine the impact of some specific events in the production that could have impacted the rating on IMDB.
For example in the following figure there is a representation of the rating of the different seasons in the modern area.
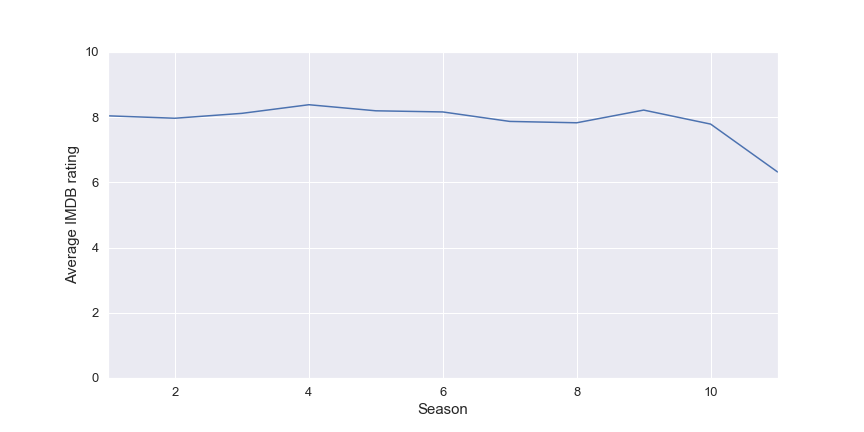
It seems that all the season have a rating really close to 8 but the last one seems to be less appreciated by the public , I think that they could be two reasons for that:
- The historical showrunner steven moffat that relaunch the sho in 2005 left the production so the new tone could not fit the audience
- The new doctor is a woman , it’s the first time in the show and after the announcement there was a shitstorm/bad buzz on the internet on the actress and as the rating on IMDB is based on user the bad buzz can impact the rating (biased by the haters)
Let’s have a look now on the casting of the show, I wanted to see if there was some name that was coming out between the two eras of the show and quite a big number, on the 3146 actors there is like 1362 actors that seems to be in the two eras , the doctor is the one that seems to have the more returning actors but it’s easy with the anniversary episodes (and the character can travel in time lol)
If we focus this analysis on the actors that are on the two eras , we can see that a good part of these actors are the voice actors for some non human characters like the voice for the Dalek played by Nicholas Briggs for example).
Let’s dive in the scripts of the episodes to start to make some text analysis with NLTK.
Analysis of the scripts with NLTK
To make the analysis of the script , I am going to use the package NLTK that is defined as
“a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries”
For this part I am going to follow the tutorial on NLTK made by datacamp, to make some processing of the scripts (tokenization, cleaning of the stopwords and lexicon normalisation) before starting to make analysis of the text.
My analysis will be divided into 3 parts:
- Get the most used words and the concordance or words
- Draw some wordcloud for some specific character
- Make some sentiment analysis
Most used words and concordance
First after the tokenization of the different sentences and words and pass the stopwords filters on the elements we can see that the 10 most popular words are:
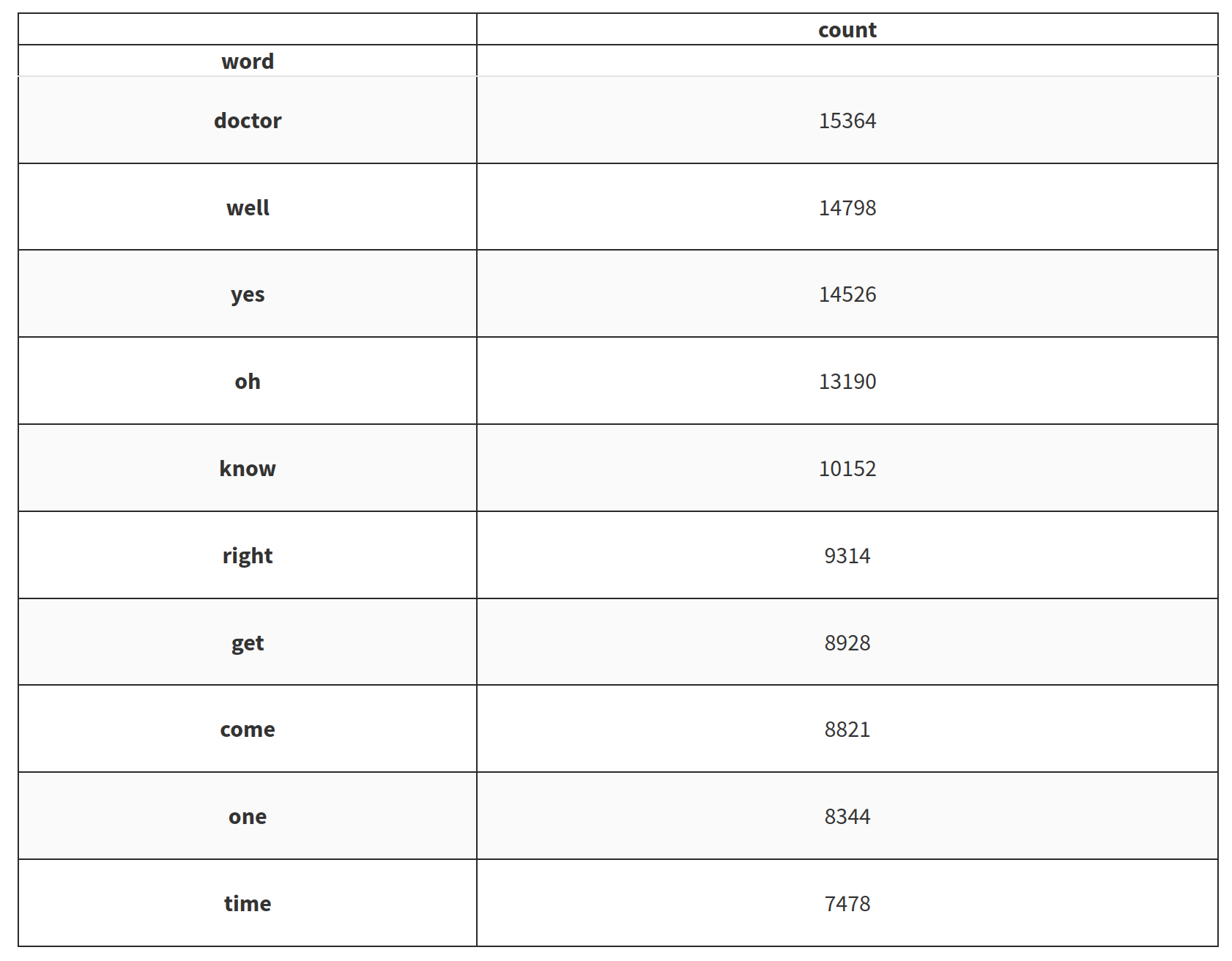
And guess what doctor is the most popular words so now let’s investigate the concordance of the word doctor with words before and after and count the occurence. There is the top 20 words that seem the most related to the word doctor.
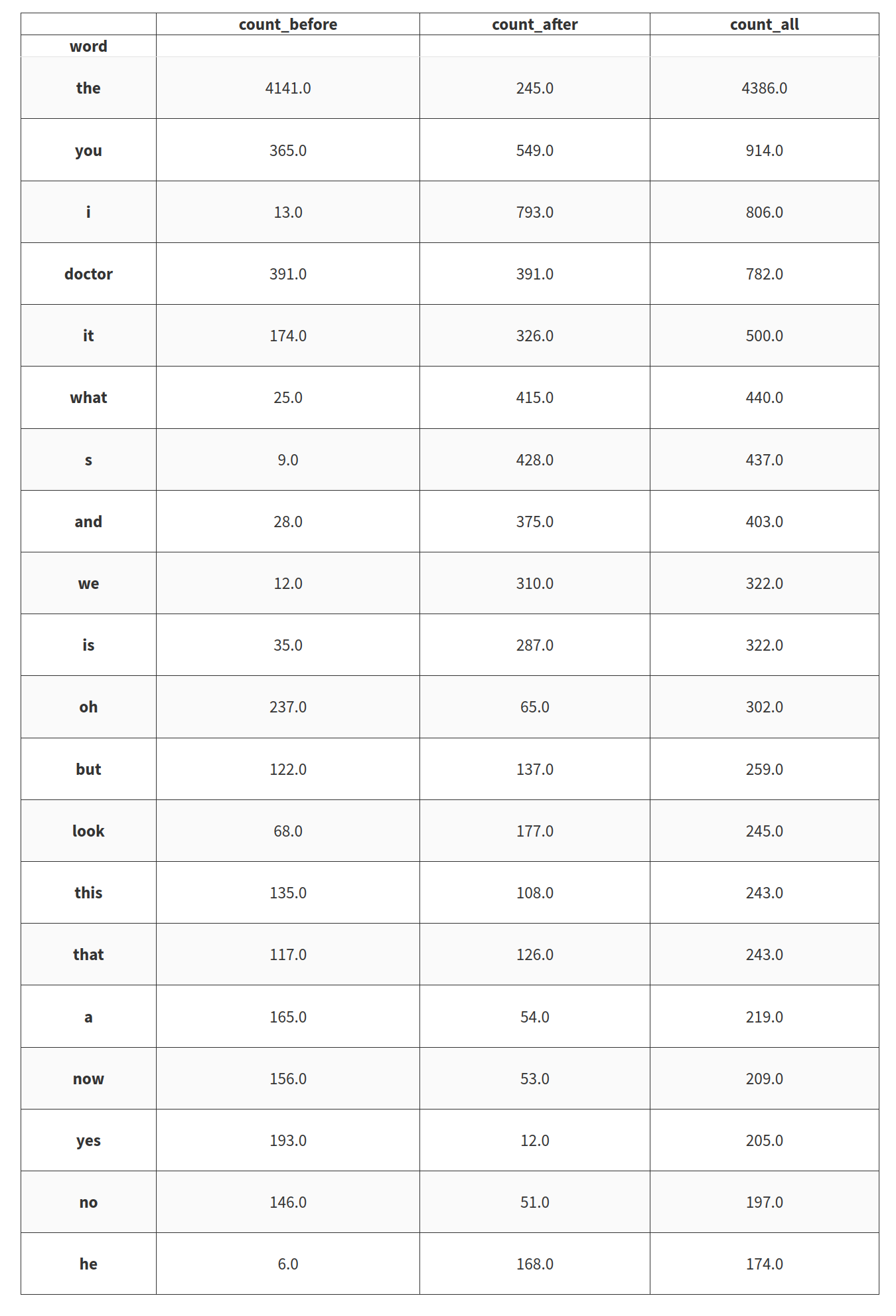
Funny to see that “the” is a good candidate for the words that are more related to doctor but it sad that “who” is not on the top 20 (it is #34). Let’s now see the words used by some specific characters.
Wordcloud
In this part I am going to determine the most used word for a selection of characters (with a wordcloud inspired by this article)
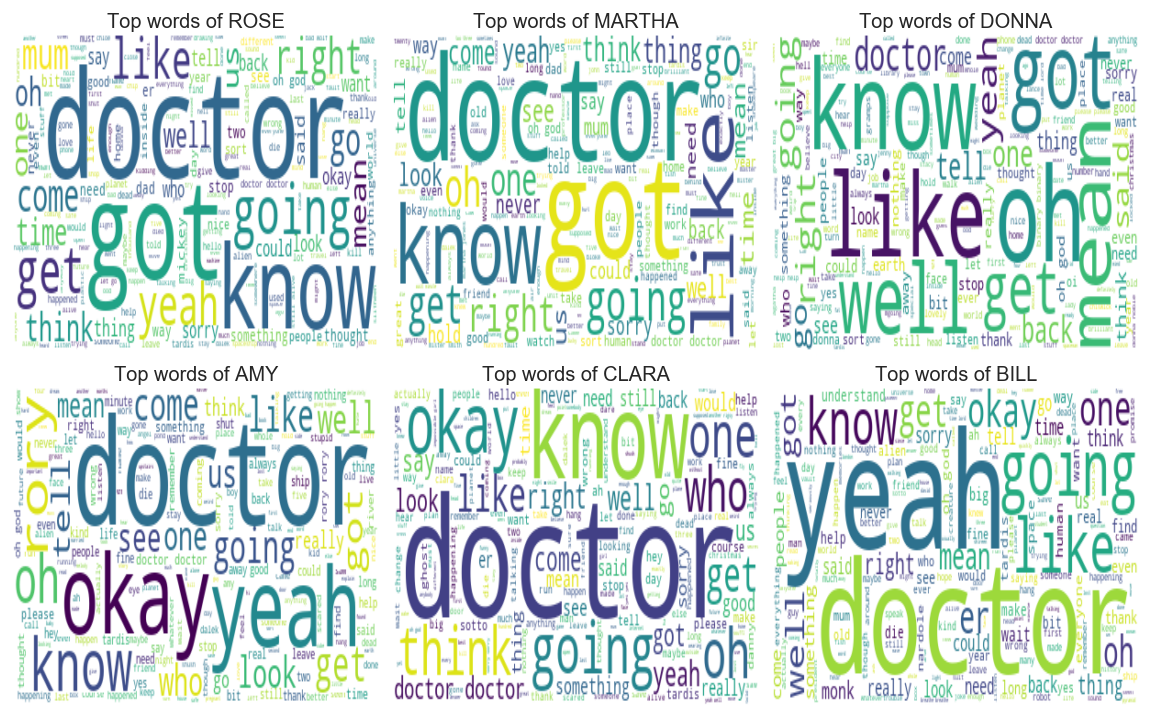
As we can see doctor is a recurring word in the mouth of a companion of the doctor. Now let’s see the word said by these crazy cans of Dalek.

Exterminate is one of the most used words by the daleks in the show, they basically want to destroy everything.
Let’s now make a little sentiment analysis on the scripts
Use of a sentiment analyser
I am going to use the sentiment analyser that can be found on NLTK call Vader sentiment analyser
The Vader analyser coming from a publication of 2014 and it is referring to the Valence Aware Dictionary and sEntiment Reasoner , and you can find an interesting article on the subject. This analyser ready to use out of the box is very useful, in the following figure there is the evolution of the speech said by the doctor during an episode of the first season.
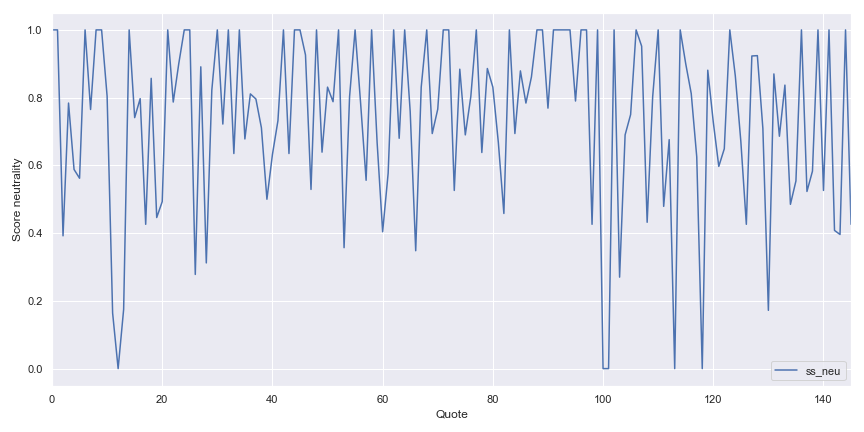
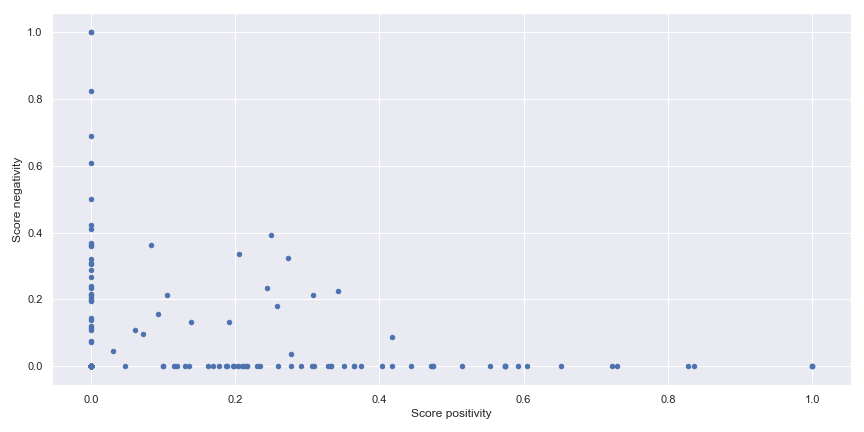
As we can see the doctor quotes are passing by different phase during an episode but most of the time the doctor is neutral on his speech. In the following figure there is another illustration of the sentiment in the quote of the doctor with a plot of the positivity and negativity of the quote.
Conclusion
This article was an introduction to my kaggle dataset with a very brief hands on NLTK, I have some ideas on things to do with this dataset and I will definitely use it to make some experiment around NLP in the future. Don’t hesitate to contact me if you have any remarks on the dataset, applications etc.







{kind=link}