
In this article, I am going to present some of my findings on my exploration of TensorFlow, the idea will be with TensorFlow to build and monitor ML models around image classification and what a better dataset than the car datasetthat I build a few weeks ago.
TensorFlow kezako?
TensorFlow is a project started in 2011 by Google Brain as a research project and that become very popular in the Alphabet group all over the years. The framework is popular in the machine learning community by its highly flexible architecture that can leverage different kinds of processing units like CPU, GPU or TPU to execute computation without big modifications of the running code.
The framework is open-sourced since 2015 and seems very popular all around the world with more than 76 000 000 downloads. There is multiple API offer by Google to interact with the framework like Python, Javascript, C++, Java and Go.
TensorFlow possessed multiples tools to produce machine learning systems:
- TensorFlow (dah)
- TensorFlow.js
- TensorFlow lite to deploy machine learning model in an embedded system
- TensorFlow Extended to productizing machine learning pipeline
- TensorFlow Quantum a “library for rapid prototyping of hybrid quantum-classical ML models”
The set of tools is very wide and really I advise you to have a look at the different documentations above that will give you a great overview of the tools.
I am just going to talk about TensorFlow, but I am planning to have a look in a few weeks on the Lite and .js tools (I ordered a device to make some tests on it 😉).
TensorFlow, how to build a ML model?
To interact with TensorFlow, one of the most popular API is the Python one (and to be honest that’s the one that I am the more comfortable with), but there are two paths available to interact with this API:
- The beginner one that is using a user-friendly sequential API called Keras
- The expert one that is using a subclassing API more pythonic
I am attaching you a snapshot of an example of the two API format
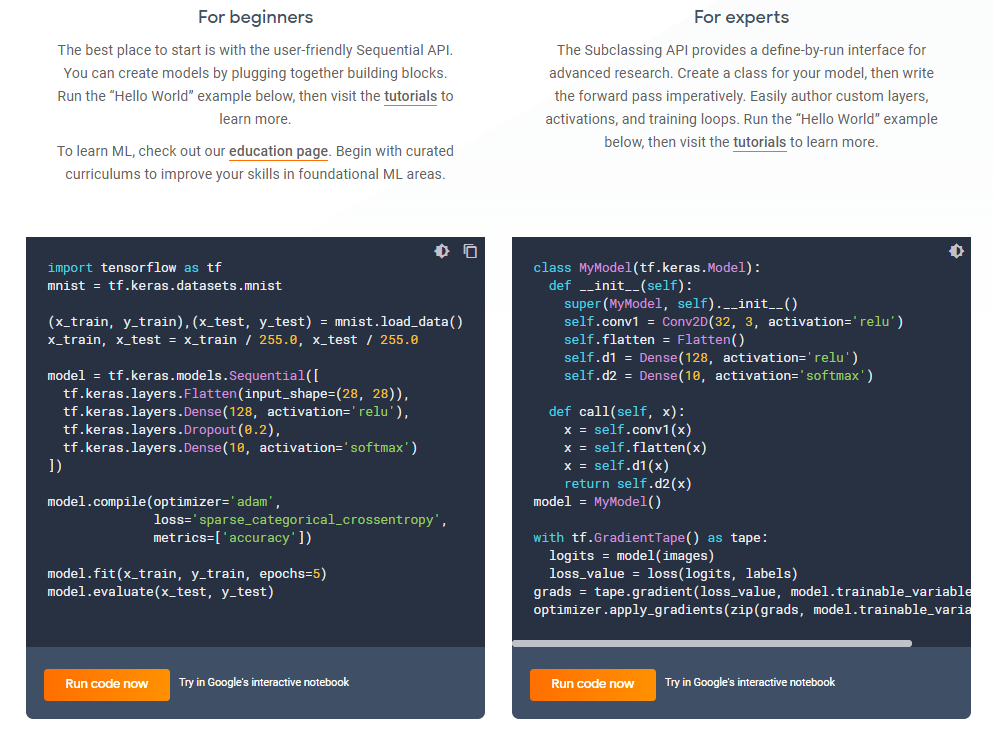
For me, I will really advise to use the Keras one that is maybe more easier to read for a non-python expert. This API originally in the TensorFlow 1.x version was not a native API (since the 2.0 it’s native) and have to be installed separately to access it.
Keras is an API that can run on top of various ML frameworks as TensorFlow, CNTK and Theano to help people to easily reused functions to build layer, solver etc without going too deep on the ml framework (an abstraction layer in some ways).
Let’s build some models to test the framework.
Model construction
In this part, I am not going to enter in an explanation of the architectures of the models that I am going to used (maybe in a specific article). To start the model building I need first to connect the framework to the data.
The data is divided between folder related to the training, validation and testing set, in each folder, there is a subfolder for each class to predict that containing all the pictures that will be used for the process. There is a graph to represent the distribution of the pictures per class in the training set.
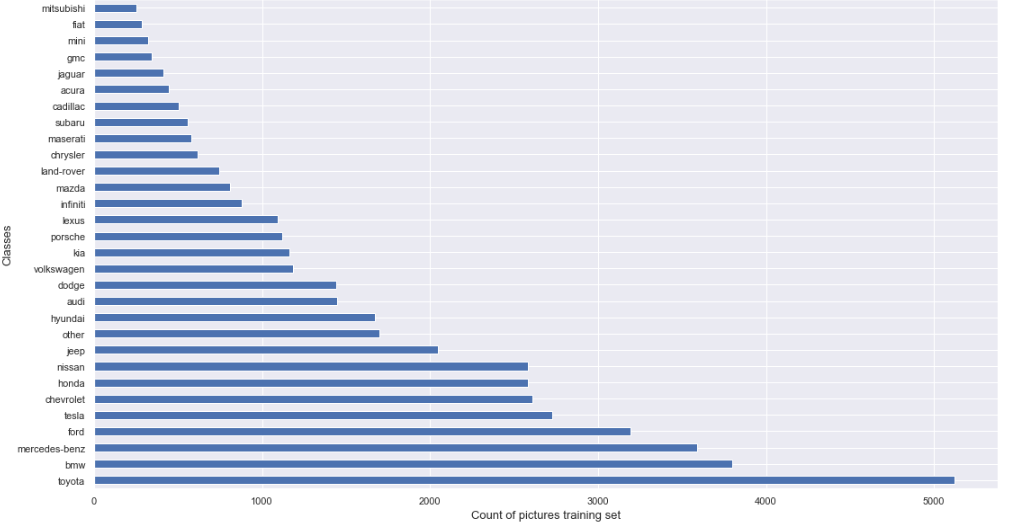
The repartition of the classes in the validation and testing set is the same that in the training set with just less data (training 80%, validation 10% and testing 10% of the full dataset).
To use the data in the model a data generator can be used like in this tutorial of TensorFlow, there is a quick snapshot of the code.
The idea of this code is to :
- Normalize the picture (RGB converted from a value between 0-255 to 0-1)
- Resize the pictures
- Build the different batches for the training
It needs to apply to all the folders, but after that everything is ready to start to the training of the model.
In term of models, I reused the model design of the tutorial of TensorFlow and applied to some other resources. The models can be found in these gists:
- The CNN tutorial of TensorFlow
- The MLP of Aurelien Geron in chapter 10 of his book Hands-on machine learning with Scikit-Learn, Keras and TensorFlow
- The CNN of Sebastian Raschka and Vahid Mirjalil in chapter 15 in their book Python machine learning
The inputs and the output of the model have been adapted to fit my needs but most of the code comes from the various resources listed. Once again these models are only there to test the framework they are not optimal for my problem (and will need a lot of refinement).
By executing the data generation and the model building the model is ready after a few minutes.

Let’s have a look now on the monitoring component of TensorFlow.
Model monitoring
To monitor your model there are two paths (for me) with TensorFlow :
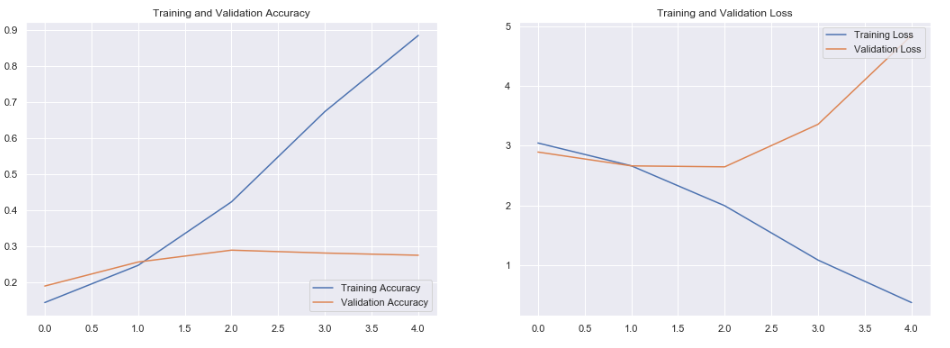
- Use the history of the model fit operation to access the various metrics that have been computed (in this case the loss and the accuracy)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']The output of history can be used to plot graphs very easily with matplotlib for example.
- The other path is to use a component called Tensorboard, it’s a package associated to TensorFlow that is offering the ability to collect in live various metrics during your run to build a model (cf gif), visualize the architecture the data etc
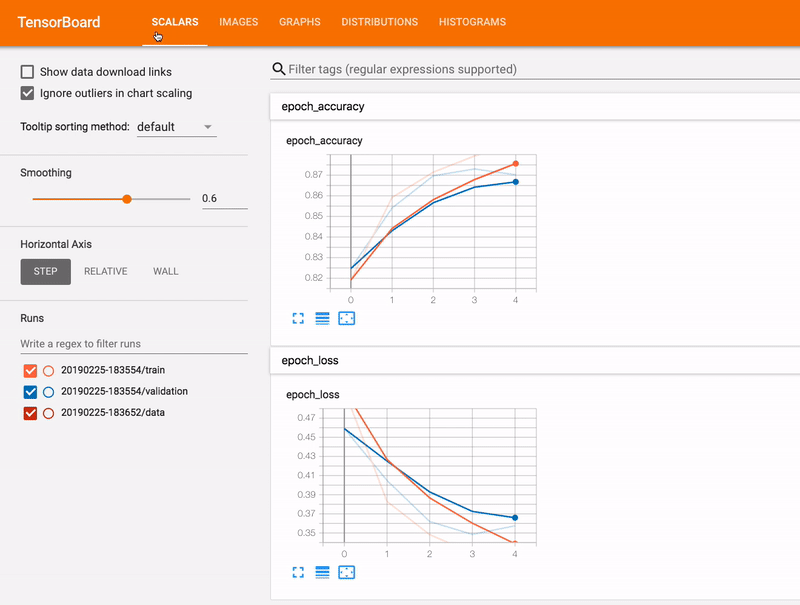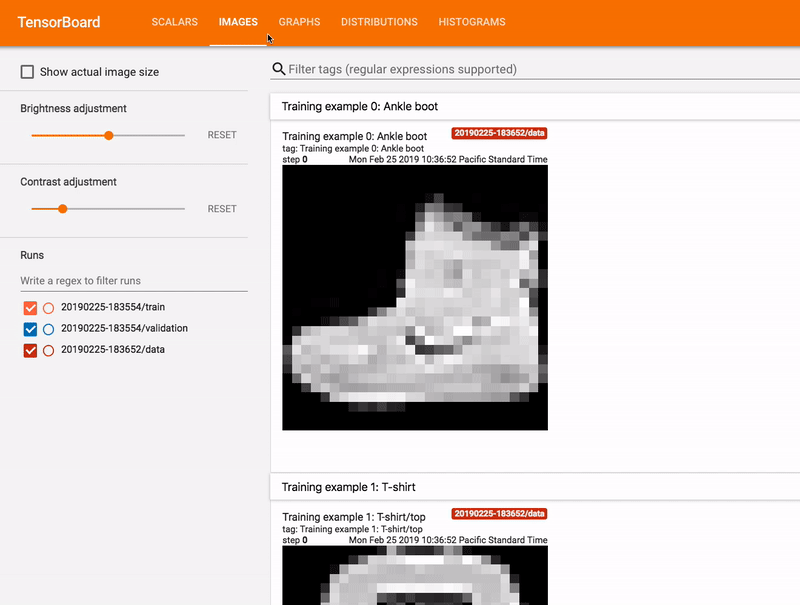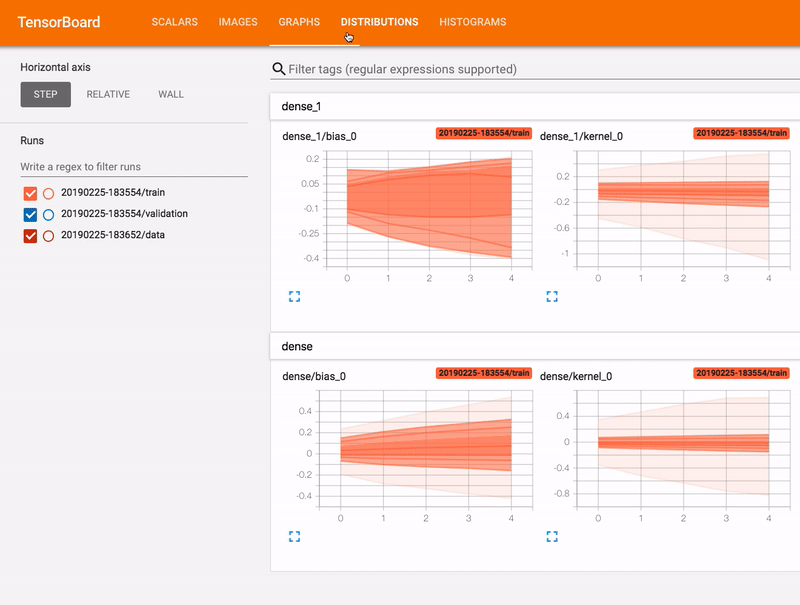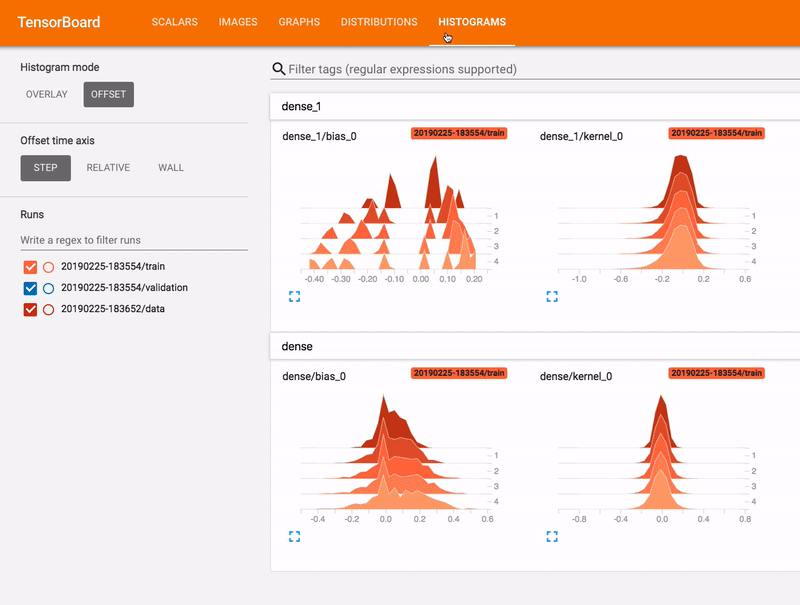
Recently Google announced the ability to share the dashboard with everybody with the tensorboard.dev initiative, you can find for example at this link a tensorboard associated with some of my runs for this project.
Tensorboad is an interesting initiative and they announced a lot of new features at the last TensorFlow dev summit but I am honestly not a very experienced deep learning practitioner so I am not very a good advocate of this component that looks complex for me but I am thinking that it could be a very nice tool for a data science toolbox in association with mlflow.
To finish on this analysis I wanted to present another component called TensorFlow hub.
Model sharing with TensorFlow hub
TensorFlow hub is born at Google from a simple situation if I am reading a really good article on some neural network architecture that looks very promising but a lot of questions can pop out during the investigation like:
- how can I reproduce this article?
- (in the case of a repo in the article) Is it the last version of the model?
- where is the data?
- (in the case of a repo in the article) Is it safe to use this piece of code?
TensorFlow hub wants to be there for people to limit all these questions and give more transparency on the ML development.
A very interesting feature of TensorFlow hub is to help people to build a machine learning model with components of famous and robust models, this approach is to reused model weights of another model and it is called transfer learning.
With TensorFlow hub, you can reuse in few lines of code components of another model very easily, in the following gist there is an illustration of a code that I built to reused a feature extractor of a model called Mobilenetv2 very popular for object classification (mostly inspired by TensorFlow tutorial).
Let’s now do a wrap-up of this analysis
Feedback
This first hands-on TensorFlow was very good, I found the tutorial pretty well done and understandable and you can really easily build neural networks with the Keras API of the framework. There is a lot of components that I didn’t test yet as it can be seen on this screenshot

I add the occasion to have a look at TensorFlow Extended (TFX) which is the approach of Google to build a machine learning pipeline, I add a try on an AWS EC2 instance but the tutorial crashed at some point but I am inviting you to watch this great talk of Robert Crowe that is presenting the tool more in details.
The approach looks very promising and I am really curious to see the interactions that will exist between TFX and Kubeflow (another ML pipeline of Google based on Kubernetes).
My only concerns/interrogations on TensorFlow is the usage of the processing unit, during my test I alternated between CPU and GPU but my monitoring of the processing didn’t show that the processing unit used at full potential (but I am maybe just a newbie).
Another path to increase the efficiency of TensorFlow is to use tfRecords, but it seems that data management is still a hot topic (from what I heard around me), I found a really interesting Pydata talk around parquet files management with TensorFlow.
My next tasks around deep learning are to:
- Do a soft introduction of Pytorch, made by Facebook it seems to be the nemesis of TensorFlow and this framework is winning a lot of traction in the research world
- Ramp-up on deep learning algorithms to build a decent car classifiers
- Understand the deployment of these deep learning models in production (data management, serving, etc)






{kind=link}