
For a few months, I wanted to test DVC, a toolkit around versioning for ML projects built by iterative. I tried it a bit at Ubisoft to see how this tool could fit into our current workflow for our ML platform, but I had the feeling that I had only scratched the surface of this library. So, a few weeks ago, Kaggle opened a competition around the design of Kaggle competition where every month (for five months), the best competition selected by the organizers won a prize for his originality and organization, so why not use this as a pretext to test DVC in this context.
Design of the Kaggle competition
For my submission to this competition, I decided to build a community competition around images and, more precisely, predict the likability of an image only based on its visual attributes. This idea is not coming from anywhere but from a previous competition hosted by Petfinder.my on Kaggle; the competition’s goal was to predict the likability of a pet’s image based on the image and extra information (manually curated).
This competition was interesting to watch (have a look at the discussion section), and I had fun participating in it (discover a few tricks for image analysis). But from this setup, I think this competition has greater use than only predicting the likability of an image but was also here to be used to build systems to advise the photographer of the pet (with the extra information that was binary) to improve his picture. I wanted to keep it simple and focus on the likability prediction for my competition, but I needed to find a suitable dataset to do it.
On my backlog of datasets for my projects (professional or personal), I had a dataset from Unsplash around images.

There is a lite version open-sourced and a full version where you need to ask for access; I will focus only on the lite one. There is a link to images (downloadable link) on this dataset and plenty of information on the searches, descriptions of images, colours, and interactions. To build my competition, I decided to keep my selection on the images and the interactions (views, downloads).
And to conclude the design of the competition, the evaluation’s metric will be the RMSE, which is very common for this kind of problem (and in the Pawpularity competition).
Let’s start to build the dataset for the competition.
Build the datasets for the competition
The structure of the competition is straightforward, and the documentation is clear. The goal of the datasets is to have a train and test datasets with extra files like images in the case of this competition.
Building the datasets is simple, but there are multiple steps defined in the following diagram.
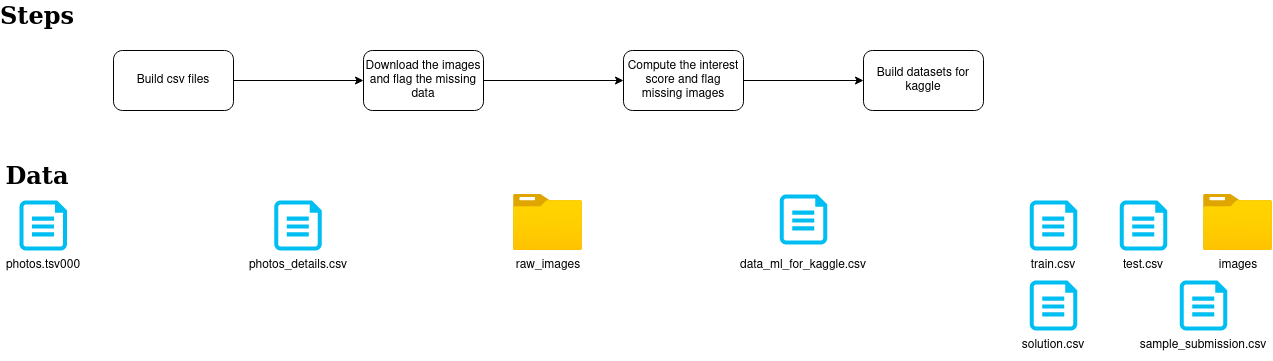
The flow is effortless with :
- a first step is to select the tsv with the valuable information related to the image and the interactions to a CSV file
- a second step is to download the images from Unsplash and store them in a folder (with their original id)
- a third step (that was the heaviest one) to compute the interest score (equivalent to the likability of the Pawpularity competition), detect missing pictures and build a new Id
- the last step is to build the files and reformat the dataset to the Kaggle requirements (for the images folder, there is a zip file for the train images and test images, it helps for the upload on Kaggle)
The different steps are a compilation of notebooks; I will not share it because it can impact the competition (and not because they are a mess ). During the development of this flow, I decided to test DVC to use this flow as a guinea pig for the data versioning features of the tool. DVC is simple to install with the following command.
pip install dvc #original install
pip install "dvc[s3]" #install with aws dependencies (be careful on it, I had to do some manual install of s3fs)I added the last component because I wanted to use an s3 bucket as the remote storage, but the local versioning could have worked great. After I followed the tutorial on the DVC website about data management, the most critical command was the following one.
dvc init # to init your DVC project
dvc add file/folder # to add a new file folder to your DVC project
dvc push # to push chnages to your dvc projectAt the first look at these commands, DVC looks very similar to Git in naming the step with the init and add actions, and DVC didn’t steal the title of Git for ML projects. However, I will be more critical of the git aspect. I will call it a **Git add-on for ML projects, **and the two last commands will help me get my point. The last two commands are equivalent to initiating the presence of this new data in the project. After their execution, there’s also an addition of files to the project.
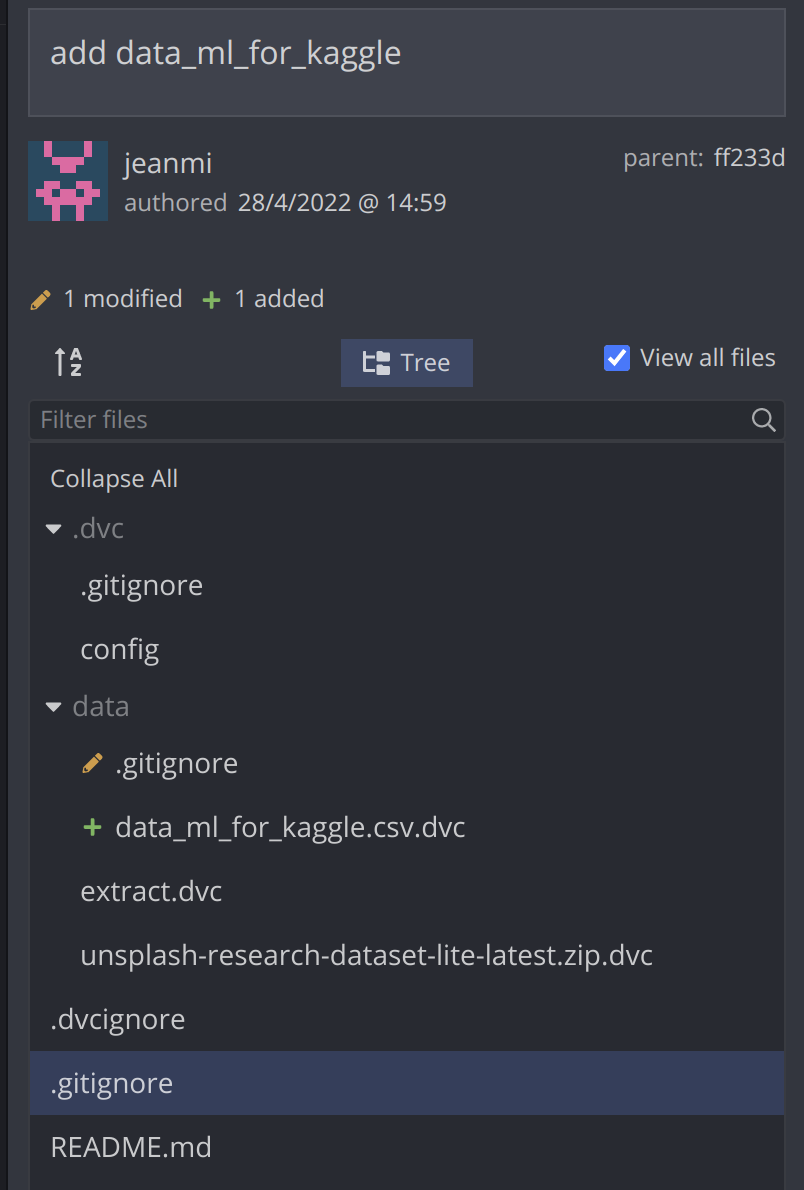
When adding a new file in the project with the command dvc add data/data_ml_for_kaggle.csv, there is an update of a gitignore tight to the data folder and a .dvc file added to the Git repository that contains detail on the new file in the remote storage.
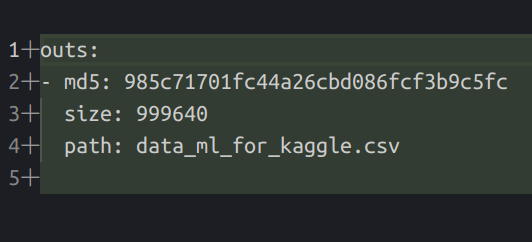
This approach offers the ability to focus only on the essential information of the data (his location on the remote storage) and the code on the Git repository. Also wit htis method you can version any files from data, model to images.
The data was only one aspect of the conception. To validate the flow of submission in the competition, there is a tool to submit submissions on Kaggle before the launch, so I decided to build a pipeline to construct random submissions and evaluate the performance of the RMSE metric used for the evaluation of the competition.
Build the submissions to test the competition
The flow for this evaluation is to:
- Build the submission
- Compute the RMSE on the public and private leaderboard (defined in the solution.csv file)
To trigger the flow, I decided to leverage the data pipeline feature of DVC (based on this tutorial) that offers the ability to build a DAG with two steps. To trigger this feature, I used the following commands.
dvc stage add --force -n build_submissions \
-p build_submissions.seed\
-d build_submissions.py \
python build_submissions.py # add a new step in the DAG
dvc repro # execute the DAGThe first command built a configuration file for the DAG and executed it by the second command. The configuration looks like this.
stages:
build_submissions:
cmd: python build_submissions.py
deps:
- build_submissions.py
params:
- build_submissions.seed
outs:
- ./data/random_submission.csv
compute_rmse_random:
cmd: python compute_rmse.py ./data/random_submission.csv ../dvc_build_kaggle_competition/data/kaggle/
./data/metrics_random.json
deps:
- ./data/random_submission.csv
- compute_rmse.py
metrics:
- ./data/metrics_random.json:
cache: falseWith DVC easily, the DAG can be displayed with a command line with dvc dag (vim’s reminder to exit this view**:q **)
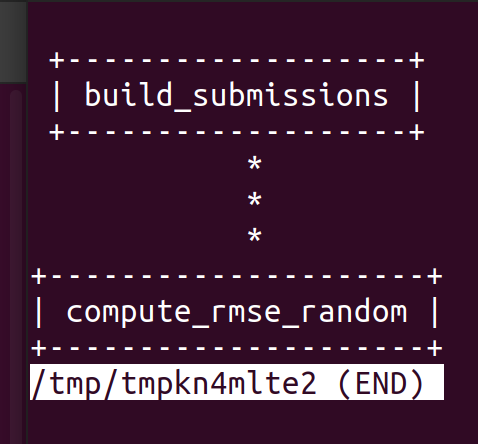
One thing also helpful when you are using a data pipeline of DVC is to build a params.yaml file that will configure the execution of the job (in my case, only containing the seed number that I want to apply to ease the reproducibility of my pipeline of random submission)
All the code that I build for this pipeline is in this repository on Github.
Another feature that can be useful in this evaluation context is the ability to build metrics. In the last step, compute RMSE, you can see a notion of metric in the configuration file (a JSON with the RMSE values on the public and private leaderboards data). This notion of a metric is handy because DVC plays the role of the orchestrator of tasks. It can also save information on the execution (in this case, the RMSE), version it with Git, and save some history on his evolution. I quickly tested my rmse locally, and the RMSE computed on the kaggle tool is pretty similar (as expected).
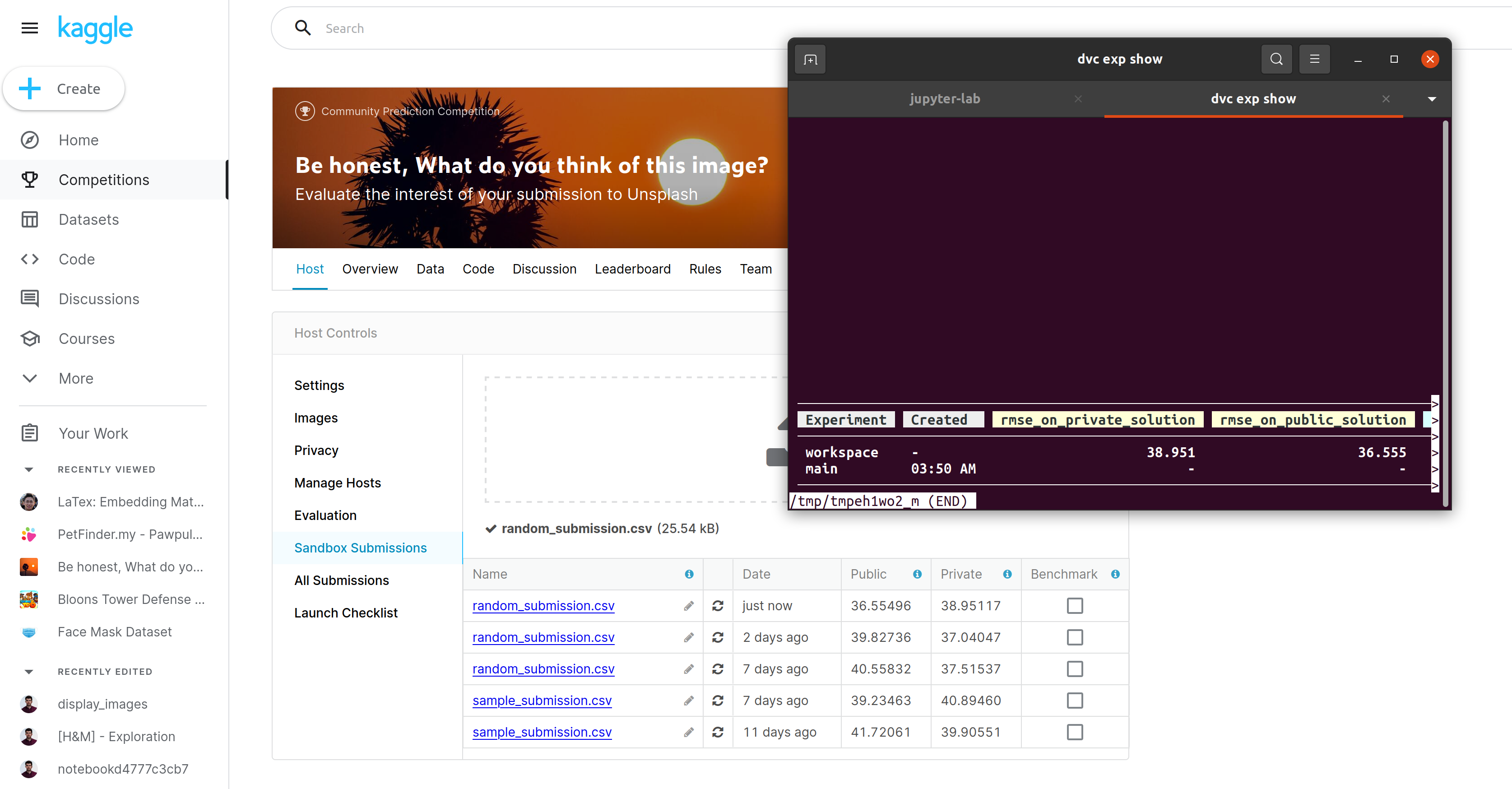
I also wanted to try a tool released a few weeks/months ago called iterative studio (originally, it was DVC studio). The tool connects your DVC project and your git repository to an interface to browse the changes and compare the various execution committed. The tool is easy to set up overall (you need to give some access), and definitely, it’s a friendly interface, but I didn’t manage to display my metrics 😶🌫️; you can find the view for my project here.
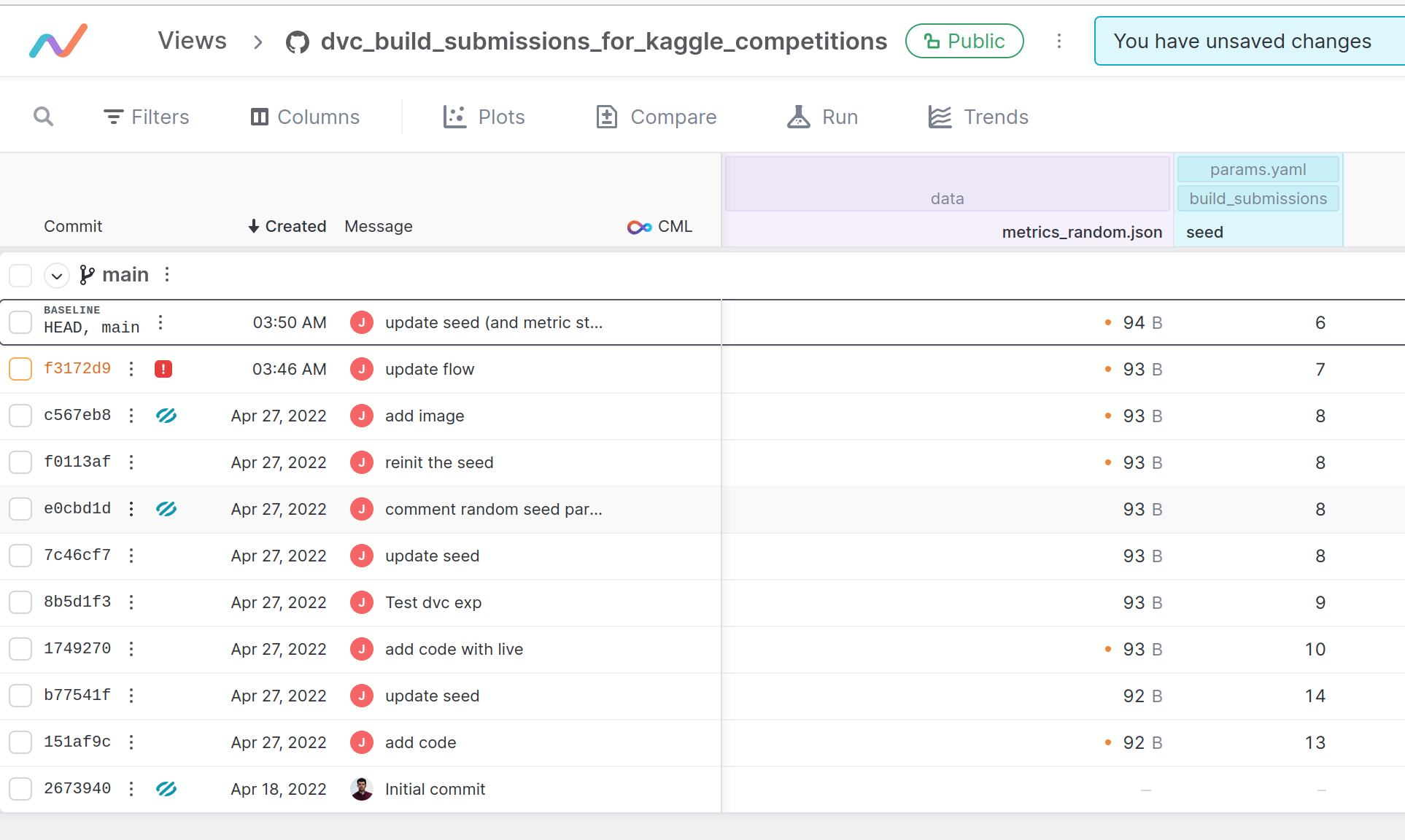
The tool offers a very nice way to check the evolution of params in the configuration file, for example (in my case, the seed for the random submission) with a link to the various commit on the repository.
Finally, and to conclude on DVC and its metric factor, DVC has a feature of logging around metrics very similar to mlflow or weight and bias called dvc live. The library seems more oriented to the model’s training with epoch (it looks like that on the demo), I tried to use it on my project, but it doesn’t make too much sense. The features in it look cool:
- connection with iterative studio
- build an HTML report at the end of a pipeline
And now we are done with the competition design.
Conclusion
If you are curious to see the competition build from this experiment (and maybe participate in it), there is the link.
Overall my experience with DVC was great, the tool is for data scientists, and the integration with Git is vital, so it eases the deployment to production and the traceability. In addition, I was positively surprised by the ability to build and execute DAG with DVC inspiring the development of the ML pipeline.
A critical component that was not obvious in this article is around the Iterative ecosystem; there is way more than DVC and iterative studio in their toolbox:
- CML, a CI/CD for ML projects, one of my colleagues made us a demo recently, and it looks super promising for the operation of an ML pipeline.
- MLEM, tool to deploy ML model (and model registry), I got my access to the beta very recently, but I think it’s promising (stay tuned)
- TPI, Terraform plug-in to manage computing resources without being a cloud expert (exciting for me )
The ecosystem seems to tackle plenty of aspects of the MLops’ problem and goes further than many solutions currently on the market.
But I have still some questions that come to my mind and that maybe some of DVC’s employees (if they are seeing this article) will be interested in discussing:
- From my perspective, in a context of an entire Spark pipeline, DVC doesn’t seem to be the right tool to version the data (writing files locally to add them to the project doesn’t seem efficient to me); what will be the suitable approach in this case?
- Automation, currently the pipeline execution, looks very manual with DVC and git commands, but in a context of a pipeline that is running predictions regularly (triggered by an external scheduler that will update a scoring set with new users and fresh features). How can DVC help in versioning the scoring set at each execution?
I hope that you enjoy the reading and that it will trigger some tests on your side.







){kind=link}