
In December 2024, we started migrating from our in-house analytics and ML platforms to Databricks. After years of building and maintaining our own stack, it became clear that adopting a modern, managed solution would help us move faster and focus on delivering value.
- Why Databricks? – The context of our switch
- DataBricklayer’s notes – Practical advice on using the platform
- Resources to Learn More – Courses and materials that helped me get started
I plan to update it over time as I am discovering new features and best practices, so keep it bookmarked :)
Changelog:
- 24 August 2025: First iteration of the article
Why Databricks?
Before diving into Databricks (DBR/DBX), it’s useful to provide some context on my situation at Ubisoft before the switch. I joined in 2018, when the company was strongly motivated to gain independence and follow the example of Uber, which was promoting its in-house ML platform, Michelangelo. This led the team that hired me to start building their own platform, called Merlin.
If you’re curious about Merlin, I presented it at PyData MTL in June 2022 . In short, it was built on top of several AWS services (but not SageMaker) and relied on open-source tools such as MLflow.
![]()
The platform delivered value for its first 3–4 years, but by 2022 it was clearly behind modern ML standards. My PyData talk marked that turning point: a team merge was imminent, driven partly by cost optimization and mutualization. These transitions are often make-or-break — and for the platform, it was a change moment. The company decided to stop building tools in-house and instead adopt managed solutions. That’s when Databricks entered the picture.

I believe in moving fast, and Databricks makes that possible. In our case, SageMaker could have worked just as well—I even ran experiments in 2020 showing this. The real question is cost: is Databricks cheaper than a lean in-house team, even if they move more slowly? Time will tell. What’s clear is that our ML platform team built a solid foundation that gave great results and paved the way for the deployment of Databricks for ML projects.
From here, let me share a few of my hacks, tips and tricks to work with Databricks.
DataBricklayer’s Notes
I won’t go into the details of each platform component here — that would require dedicated articles. Instead, I’ll focus on the main pillars of the platform that are data and compute, coding, and visualization/machine learning , and the hacks, tips and tricks that I found linked to them.
Data and compute
Create volume: Volumes are not well-advertised on the platform, but they are very useful. In my case, I use them to store images, to trigger job flows when a specific file arrives in the volume or just store files in a CSV format in a more persistent way. It’s not difficult to create a volume, but I wanted to share the create statement:
In my projects, which usually deploy ETL and ML code across multiple environments and targets, I find it useful to be able to create the same volume in the schemas linked to each of the place of the project.
Delta format: Delta format offers many features, but the most useful is time travel with table versions. You can easily go back in time by checking version of the table, or a specific timestamp (that is not a column of the table)
I am using this feature to check the status of previous predictions for a batch pipeline without having to keep a history table.
Liquid clustering: At work, we had the habit of partitioning some of our large tables. On Databricks, you can cluster tables using Liquid Clustering. You can define the clustering key or let the table adapt itself (with auto clustering).
I compiled a few PySpark/SQL commands in a gist to interact with liquid-clustered tables.
Compute naming convention: It is useful to define naming conventions when creating compute resources. By default, Databricks generates names based on your username and creation date, but these can be long and hard to read. I created my own convention, inspired by what we used on the Merlin platform, and designed this schema.
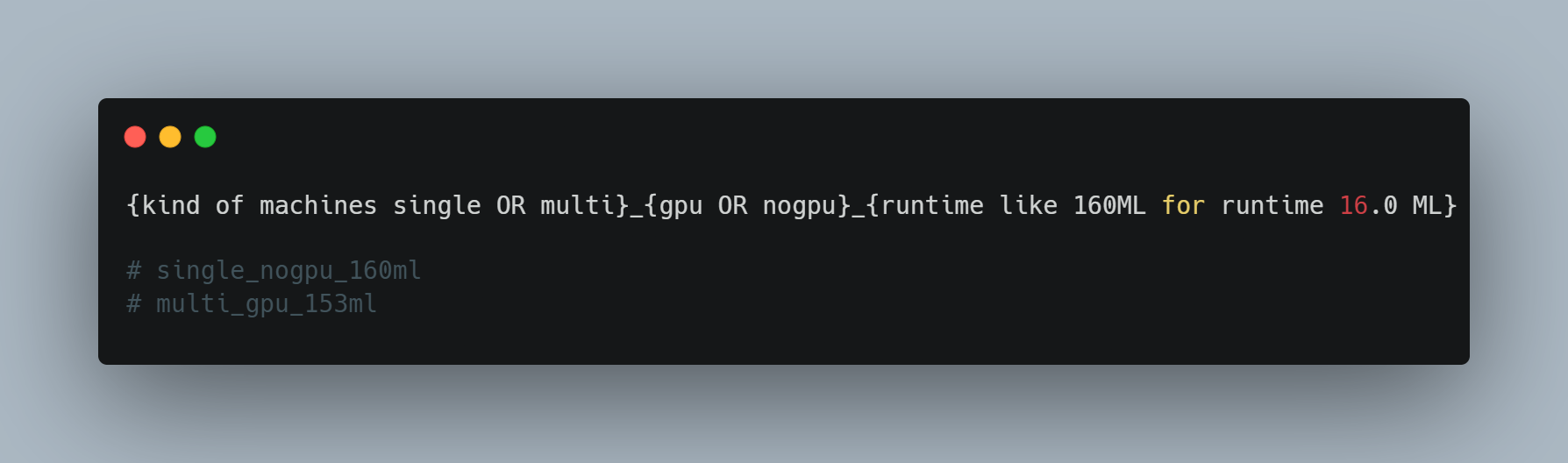
This makes it easier to track your resources and switch between them, for example using the dropdown in the Web UI.
Inactivity threshold of a compute : By default, Databricks sets the timeout to 20 minutes. From my experience, a better threshold is 120 minutes. This helps if you go to a meeting or forget a long-running job, as it avoids waiting for the machine to restart.
Don’t use the most recent runtime: Databricks iterates quickly, releasing new runtimes with the latest versions of Scala, Spark. However, a small delay in adopting a new runtime can be beneficial. For example, in January 2025, while exploring their recommender system resources, I found that they were based on runtime 14.3 even though 16 was about to be released
Code
Dbutils functions selection: Databricks Utilities (dbutils) is a built-in library, installed on all deployed compute resources, with many functions to interact with Databricks components
The code snippet below shows my go-to functions for working with it thse days
Prototype jobs on the web interface first :
When deploying a Databricks job via a data asset bundle (DAB), the resource YAML file contains the job configuration. This file can be long and have many levels of indentation.
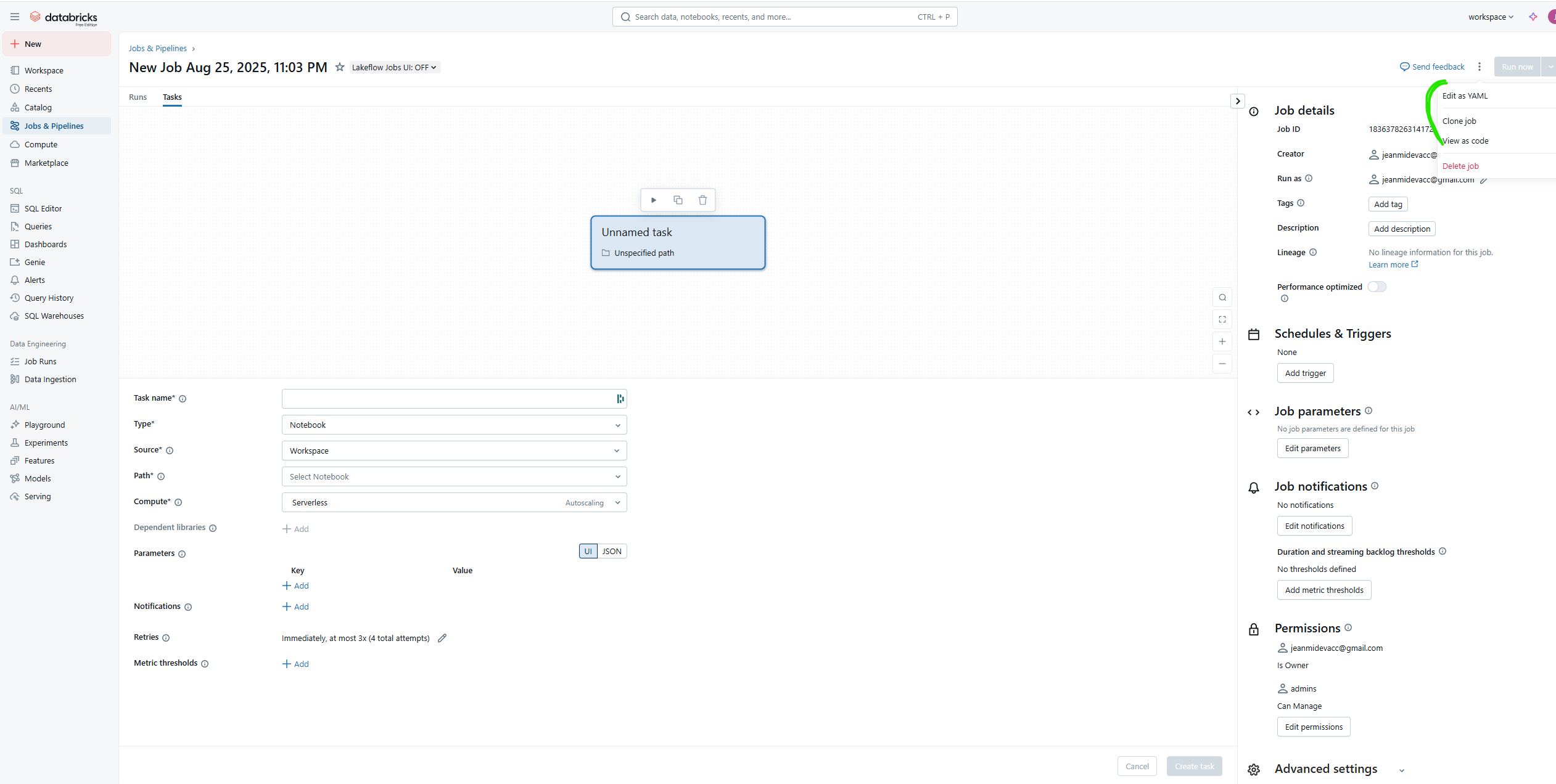
My advice is to design these files first using Databricks’ Web UI and the “View as Code” button at the top right. This is also an efficient way to explore different schedules, triggers, dependencies, and condition mechanisms.
Databricks CLI profile: In my job, I need to interact with different workspaces for different projects. Therefore, I have to identify myself in the CLI to deploy code in these workspaces easily and switch quickly. One approach is to create Databricks CLI profiles using the databricks auth command, which sets variables locally like this.
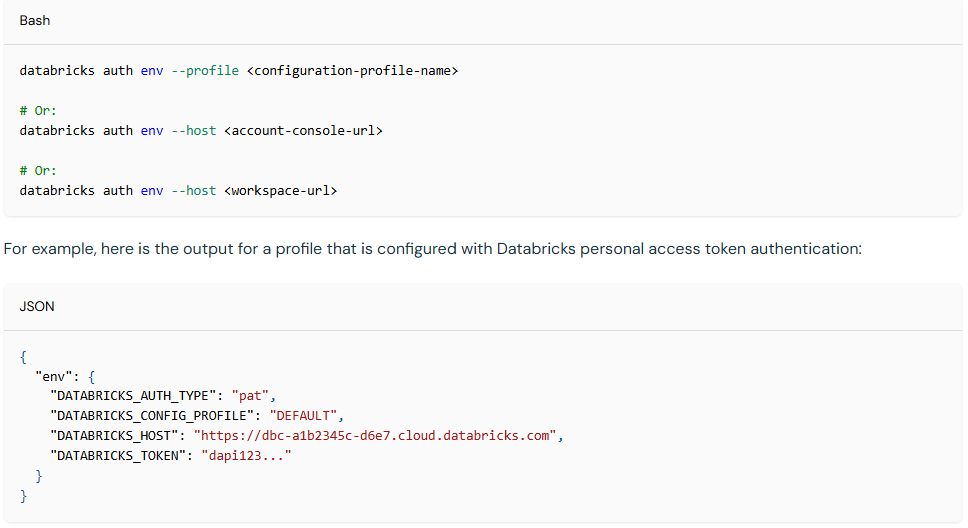
It’s very similar to AWS profiles in a way. The setup can be done in a few seconds, which helps avoid headaches and ensures code is deployed in the right place.
DAB configuration: When deploying DAB, beyond the resource files that contains the job organization and the code deployed in the workflow folder, there is also the databricks.yml file, which contains the general configuration of the project.

In the databricks.yml file, you can define various environment variables that can be customized based on where the code will be deployed (staging, deploy and/or dev/uat/prod). You can adjust the variable for the specific place deployed. Usually, I am using the variable to set:
- Job schedule: You could delay or accelerate some test environment executions
- Resource size: Like min and max workers, useful to reduce the default computing resource in UAT versus PROD for example
- Schema: The location where the data will be stored for the code running in
- Paused/unpaused jobs: You could easily switch off the execution of all jobs
Trigger jobs from another job: This one is more of a hack, but when I started operating jobs, I needed to chain two jobs after another one and didn’t know the best way. At first, I used the trigger condition based on file arrival. I completed my first job with a step that wrote a dummy file into a schema volume linked to the next job.
I don’t think this is the best approach, and after discussing with colleagues, I learned I could probably build a job that directly trigger all the jobs together. Still, it was a nice shortcut at the time.

Backload data with job: This one comes from advice by my colleague Simon. When you need to backload data for a system (for example, all the data from previous AC RPG games as a random example :) ), the For Each step in Databricks jobs is my way to run a task repeatedly within a job.
Visualization & Machine learning
Databricks apps: This is one of the main killer feature of the platform. Deploying web apps was always a struggle in my job, at least to do it autonomously. The Databricks app unlocked that, while also adding an extra security layer for data accessibility, which is often the main pain point.
Deploying the app is easy, but sometimes interacting with the data can be tricky. Databricks made onboarding easier by providing a GitHub repository and an app cookbook to help with this.

The transition from local development to online deployment is still not smooth (I am currently working on some code snippets to improve this). However, it already enables many new use cases for data scientists.
AI/BI dashboard template: Databricks has its own BI visualization tool called AI/BI. It offers the ability to create dashboards that are easy to share and also provides an extra layer of “AI exploration.”
Beyond simple usage, I want to highlight the ability to create templates from dashboards that can be exported as JSON files. These exports include both dataset statements and figure designs, so you can easily reuse dashboards from project to project.
Interaction with LLMs: Databricks, beyond allowing you to deploy LLMs on the platform, also offers the ability to use foundational models from different providers such as LLaMA, Mixtral, DeepSeek, Gemma, and, more recently GPT OSS. It’s very straightforward: you can interact through the OpenAI client in Python, or by sending HTTP requests to specific endpoints if you prefer.
But the most interesting feature to interact with LLMs is the AI SQL functions. Multiple types of functions serve different purposes (see picture).
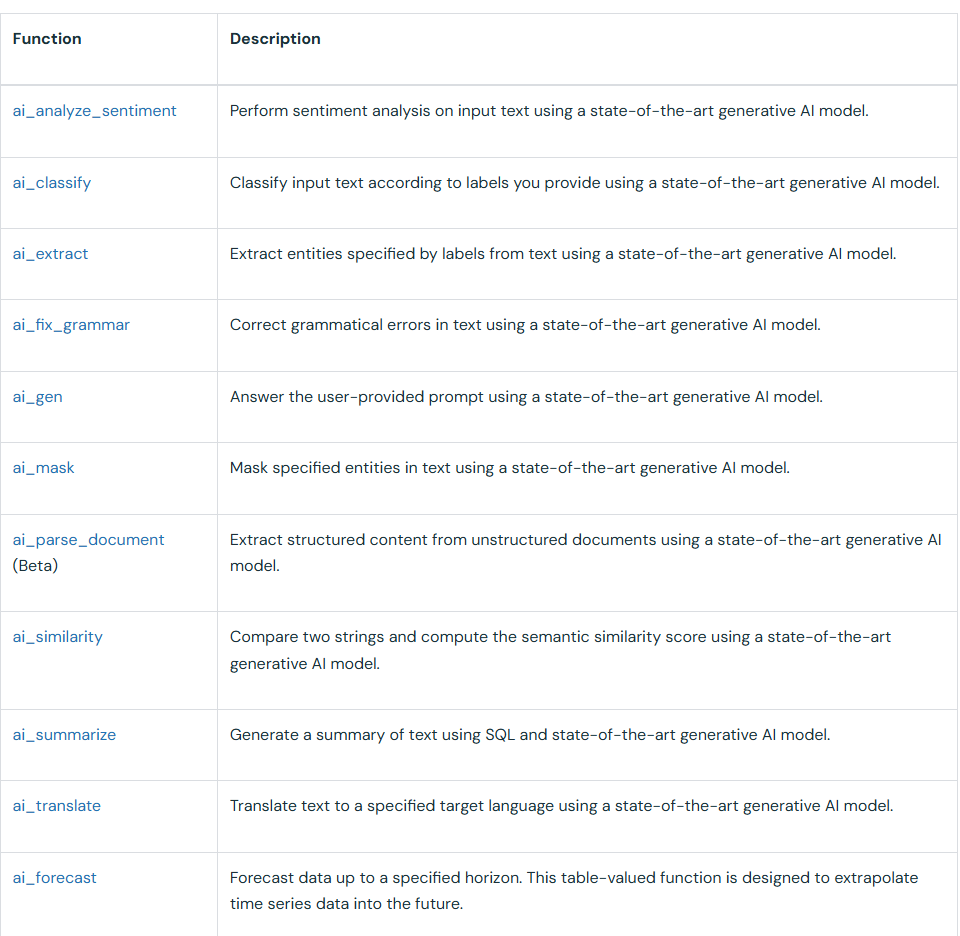
The most interesting one is the ai_query, which is hidden from this list. With this function, you can provide the model name and the prompt you want to apply to the content stored in a specific column of a Databricks table. This allows you to easily make batch calls to manipulate any table with an LLM.
The ai_query can also be embedded in a UDF function, which can then be shared with others. This makes it really convenient to version and reuse functions across projects.
Resources to Learn More
When we started our onboarding on Databricks, one of the first things that the platform team asked us to do was to explore the Databricks Academy to learn more about the platform.
During my onboarding, I focused on the following three courses:
- Databricks Fundamentals
- Data Preparation for Machine Learning
- Machine Learning in Production (V2): This course is currently retired/under maintenance
These resources cover a large part of the fundamentals necessary to operate machine learning in production on the platform. Based on my experience migrating ML projects to Databricks and using DAB extensively, I also recommend looking at courses around DAB, such as Automated Deployment with Databricks Asset Bundles, which help you better understand how it works.
Beyond taking certifications or watching videos in the academy, practicing with the platform is definitely useful. Recently, Databricks announced the Databricks Free Edition, which replaces their Community Edition. It allows you to explore some of the main features of the platform at no cost. The experience is limited, but I strongly advise anyone applying for a data role at Ubisoft (or any companies where Databricks is part of the ecosystem) to try it.
Finally, if you want another perspective on Databricks, I highly recommend:
- The course MLops with Databricks by Maria Vechtomova and Başak Tuğçe Eskili from Marvelous MLOps . It provides a good introduction to MLOps on Databricks using the Free Edition
- Having a look at the replays of the AI + Data conferences, which usually compiled talks from external users of the platform with keynotes from Databricks
What’s next
So, what’s next for me ? After migrating the machine learning side of my projects to Databricks, the second phase is to migrate the ETL/analytics side. I am currently heavily involved in replugging my pipelines on Databricks, but there are a few things ahead that I am excited to explore:
- Live model serving: My projects currently only use batch model serving. I have experimented a bit with some PoCs around live model serving, and this will be the next big step to understand how to operate this type of workflow on Databricks.
- MLflow enhancements: Interestingly, I haven’t used MLflow much yet on Databricks (though I was a heavy user on the previous platform). There are plenty of new features in the latest version that will be useful for some of my projects
- Brick Agent & all the LLM stack: That was one of the big announcements at the last AI + Data conference, Databricks now offers a collection of services around agent creation that looks promising based on the replay. However, I don’t yet have a concrete use case with a real data system that needs this kind of application, so I will wait for the right opportunity to experiment with it.

Beyond this article, I enjoy discussing data, AI, and system design—how projects are built, where they succeed, and where they struggle.
If you want to exchange ideas, challenge assumptions, or talk about your own projects, feel free to reach out. I’m always open for a good conversation.





{kind=link}