
Filtrage collaboratif et système de recommandation à deux étapes avec Surprise
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Cet article va creuser dans un package Python sur le système de recommandation dans mon radar. Le package est défini comme un package Python scikit pour construire et analyser des systèmes de recommandation construits sur des notes explicites où l’utilisateur note explicitement un élément, par exemple, un pouce levé sur Netflix (comme dans l’image suivante avec l’émission de télévision Formula 1 sur mon compte).
L’article se concentrera sur les principales fonctionnalités du package que j’appliquerai au jeu de données Sens Critique que je construis depuis quelques mois pour mes expérimentations autour des recommandations (cf article précédent)
Le package Surprise utilisé pour cet article est la version 1.1.1.
Gestion des données
Pour exploiter le package Surprise, vous avez plusieurs chemins possibles :
- Utiliser des jeux de données intégrés : le movielens-100k/1m et jester (un jeu de données de blagues) sont disponibles
- Ou utiliser votre jeu de données, vous pouvez charger des fichiers ou un dataframe pandas
Le package est flexible et facile à utiliser, mais vous devez respecter un certain formatage lorsque vous manipulez votre jeu de données ; les colonnes de vos données tabulaires doivent être ordonnées comme cela.
- Utilisateur
- Article
- Note
- Horodatage (optionnel)
Ce format est très courant pour un jeu de données de recommandation mais toujours bon à garder à l’esprit.
Pour cet article, j’ai décidé de continuer mon expérience avec les mêmes sources de données que dans mon article précédent sur les métriques d’évaluation, en changeant simplement le cadre temporel. Par conséquent, il y a un rapport datapane sur les données utilisées pour cette expérience.
L’idée sera d’utiliser toutes les critiques/notes que j’ai jusqu’au 1er janvier 2022 et de prédire la note associée à une paire utilisateur/article la semaine suivante.
Pour l’expérience, j’ai également inclus dans l’ensemble d’entraînement quelques faux utilisateurs qui seront des archétypes d’utilisateurs (mais je les expliquerai plus en détail si nécessaire) pour aider à analyser les modèles produits pendant l’exploration du modèle.
Un élément essentiel est que les données doivent être formatées dans un format Surprise ; il y a une illustration du processus pour le DataFrame pandas.

Le format est pratique car il encodera les identifiants d’utilisateur et d’article pour répondre aux besoins de la construction du modèle dans l’entraînement (et cet encodage sera conservé après le calcul de la recommandation).
Pour construire ce modèle, voyons d’abord ce qu’il y a dans la boîte à outils de Surprise en termes d’algorithmes.
Exploration des modèles
Dans Surprise, la plupart des algorithmes sont structurés autour des approches de filtrage collaboratif (CF) des systèmes de recommandation ; il y a une leçon de Stanford sur ce type d’algorithme qui peut être utilisée comme une bonne référence pour les praticiens ML.
Dans le package, il y a les groupes d’algorithmes disponibles :
- Aléatoire
- Ligne de base
- Factorisation matricielle
- KNN
- Slope one
- Co clustering
Je ne détaillerai pas les différents modèles mais fournirai quelques ressources si vous êtes intéressé à en savoir plus sur eux (tous les articles derrière ces groupes sont ici).
Aléatoire: Cet algorithme est assez simple et donne une prédiction aléatoire pour la note d’une paire utilisateur/article basée sur la distribution de la note dans l’ensemble d’entraînement (qui devrait être normale)
Ligne de base: Dans ce groupe d’algorithmes, il y a deux algorithmes disponibles :
- ALS (Alternating Least Square), qui est très populaire dans le filtrage collaboratif qui est une technique très populaire pour faire du CF, il y a une vidéo qui explique l’implémentation dans pyspark (que j’utilise au quotidien)
- SGD (Stochastic Gradient Descent): Un algorithme assez connu en apprentissage automatique, mais il y a un rappel rapide juste au cas où.
Si vous voulez en savoir plus sur ces algorithmes, il y a plus d’explications dans l’article à la source de leur implémentation.
Factorisation matricielle: Sur ce groupe de modèles, il y a 2,5 algorithmes différents :
- SVD (Single Value Decomposition), cet algorithme est une technique de réduction de dimensionnalité ; voici un bon article du collège Carleton sur le sujet. Cette méthode a été popularisée par la solution gagnante du prix Netflix de Simon Funk. Le 0,5 est lié à la version SVD++ du SVD qui est également détaillée dans l’article de Koren.
- NMF(Non-negative Matrix Factorization): Le principe de cet algorithme est très similaire au SVD, et l’implémentation est basée sur les articles suivants The Why and How of Nonnegative Matrix Factorization et Stability of Topic Modeling via Matrix Factorization. Si vous voulez plus de détails, il y a une explication vidéo.
KNN: Pour ce groupe d’algorithmes, le processus est un dérivé de l’algorithme k-nearest neighbours mais appliqué sur la note utilisateur, article, et il y a une implémentation différente possible, comme nous pouvons le voir sur la documentation. Cette vidéo a une répartition de l’approche derrière ce groupe d’algorithmes.
Un paramètre critique (si nous allons plus loin que le nombre de voisins) est la fonction de similarité est également très importante.
Slope One & Co-clustering: Pour ces deux algorithmes sont en quelque sorte uniques mais font écho aux autres algorithmes du package, il y a plus de détails dans l’article derrière l’implémentation :
Enfin, sur ce package, comme dans l’héritage scikit, il y a aussi la possibilité d’avoir des stratégies intéressantes pour entraîner des modèles avec :
- Itérateur de validation croisée : Capacité de faire des Kfolds etc., mais je mettrai en évidence un itérateur appelé LeaveOneOut qui est très intelligent dans le contexte de la construction de modèles de filtrage collaboratif (laisser sur l’ensemble de test x note pour un utilisateur dans l’ensemble d’entraînement)
- Recherche en grille: Recherche en grille pour trouver les paramètres
Il y a de nombreux scripts dans le dépôt GitHub pour illustrer comment les utiliser.
Maintenant, voyons comment les algorithmes peuvent s’adapter au jeu de données de sens critique.
Construire un système de recommandation
Comme mentionné au début de l’article, l’objectif de cette expérimentation est de construire un bon classeur de paires utilisateur, article dans le sens critique ; j’ai décidé de me concentrer uniquement sur trois modèles :
- NMF
- KNN articles avec ALS pour la mesure de similarité
- KNN utilisateurs avec ALS pour la mesure de similarité
Comme le modèle construit peut estimer la note explicite potentielle qu’un utilisateur peut donner à un article, j’ai décidé de concentrer ma recherche de paramètres en optimisant la métrique rmse. Cependant, je vais également enregistrer le temps d’entraînement et le temps de calcul de la période de test. Pour mon exploration et pour la rendre plus efficace, j’ai construit un système rapide avec :
- hyperopt pour optimiser ma recherche de paramètres
- enregistrer mes résultats dans mlflow pour faire ma sélection de paramètres après.
Il y a un Gist de code pour présenter le processus pour le NMF
Pour comparer les performances des modèles, j’ai décidé d’utiliser
- le prédicteur aléatoire du package pour faire une note aléatoire
- Un ConstantScorer donnera à toutes les paires utilisateur/article la même note.
Il y a une représentation du rmse pour les modèles sélectionnés et les lignes de base.
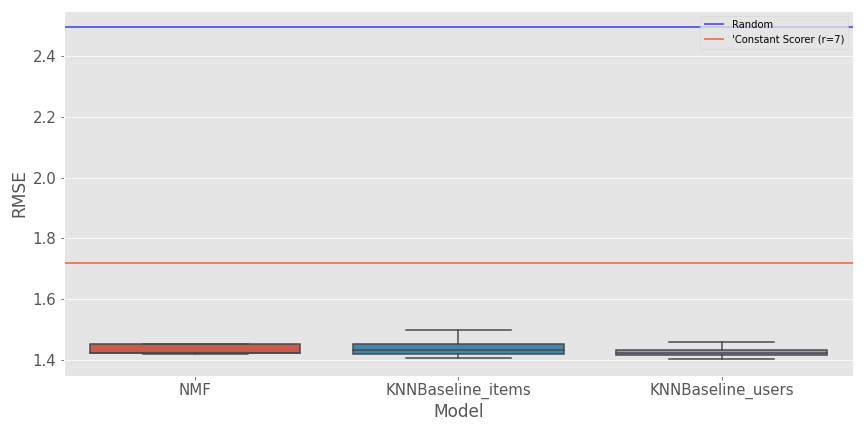
Dans l’ensemble, il semble que la barrière de 1,4 soit difficile à battre (sur le temps et l’espace de recherche que j’ai alloué), et les trois algorithmes semblent avoir des résultats très proches. Le résultat n’est pas fou (ne pas avoir quelque chose sous un RMSE de 1), mais le système apprend les relations entre utilisateur et article par rapport aux modèles de base. Dans ce deuxième graphique, il y a une comparaison du temps d’évaluation et du temps d’entraînement pour les différentes expériences.
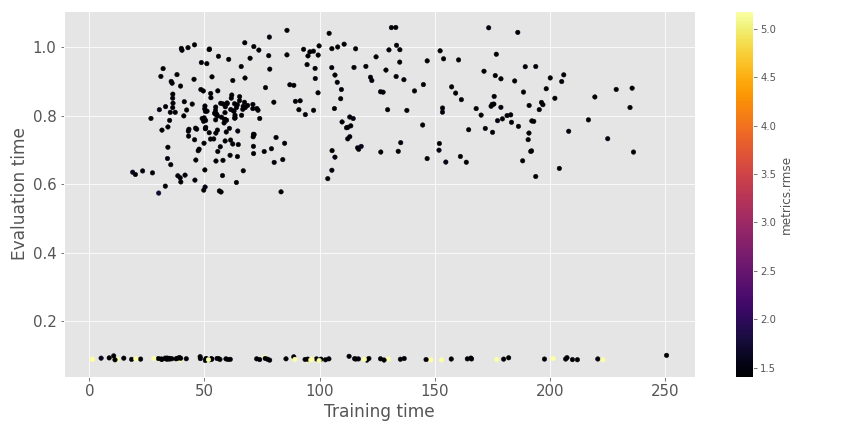
Les temps ne sont pas si longs comme nous pouvons le voir avec notre ensemble d’entraînement de 1 million de lignes :).
Pour mieux comprendre les prédictions des modèles, j’ai décidé de prendre le meilleur modèle de chaque algorithme et d’évaluer comment ils fonctionnent sur les archétypes. Ces archétypes sont des utilisateurs qui ont un goût spécifique et classent des articles spécifiques ; il y a les détails sur les archétypes :
- Marvel fanboy: Un utilisateur qui aime beaucoup les films de l’univers cinématographique marvel et n’aime pas le contenu de l’univers DC

- RPG lover: Un utilisateur qui aime les jeux RPG en général mais pas trop les autres grands jeux réguliers (comme FIFA ou call of duty)
- French connoisseur: Utilisateur qui aime les vieux films français, mais pas les autres types de films (essayé de prendre des films du MCU et des films populaires non français)

Pour construire des recommandations (comme première itération), l’idée maintenant est de classer le catalogue et de trouver l’article avec la meilleure note prédite par le modèle. Il y a un gist pour présenter la fonction de calcul.
Rien de vraiment fantaisiste, j’utilise juste le modèle calculé avant avec le catalogue d’articles que je classe. Alors maintenant, voyons les recommandations du NMF pour les archétypes.

Très similaire pour chaque archétype (sauf le witcher dans l’histoire du fan RPG). Il y a des recommandations des lignes de base KNN (articles) pour les archétypes.

Encore une fois, conclusion très proche que pour le NMF … Et pour conclure, il y a des recommandations de la ligne de base KNN (utilisateurs).

Il y a un peu de diversité dans ce cas, mais les recommandations n’ont pas trop de sens (sauf pour Chrono trigger pour le fan de RPG).
Les résultats de ces prédictions m’ont assez choqué, mais je pense que cela peut venir de plusieurs choses :
- J’ai optimisé le score de la paire contenu utilisateur dans ma recherche d’hyperparamètres, n’essayant pas d’optimiser les métriques de prédiction de recommandation (comme le taux de réussite ou NDCG)
- Le jeu de données est très inhabituel, je pense, pour le monde de la recommandation avec plus de contenu que d’utilisateurs, donc certains biais peuvent en provenir.
À partir de ce dernier point, j’ai creusé un peu plus dans ces contenus, et j’ai remarqué les détails suivants.
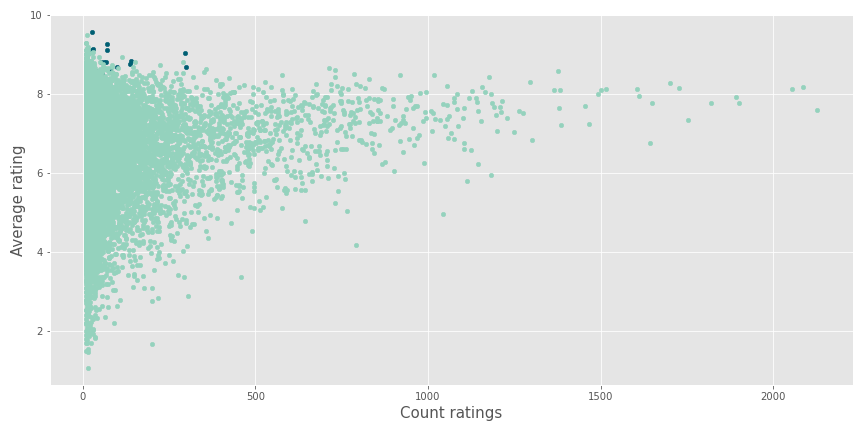
Les contenus recommandés (en bleu foncé) semblent être des valeurs aberrantes avec quelques critiques et une excellente note moyenne.
Donc le calcul des recommandations doit être retravaillé (la méthode actuelle n’est pas évolutive et pas précise) et un chemin possible est le système de recommandation à deux étapes/stages.
Construire un système de recommandation à deux étapes
Cette approche est à la mode dans les systèmes de recommandation, facilitant généralement le calcul de manière en ligne. Eugene Yan fait un excellent article sur le sujet.
Let's explore how recsys & search are often split into:
— Eugene Yan (@eugeneyan) June 30, 2021
• Latency-constrained online vs. less-demanding offline environments
• Fast but coarse candidate retrieval vs. slower and more precise ranking
Examples from Alibaba, Facebook, JD, DoorDash, etc.https://t.co/zTsfElLw1z
L’idée derrière ce processus est d’avoir deux phases pendant le calcul avec :
- Récupération: Trouver le contenu approprié (candidats) pour l’utilisateur à classer
- Classeur: Classer les candidats
Dans mes deux derniers récapitulatifs recsys(2020, 2021), j’ai mentionné quelques articles autour de ce type de pipeline que je vous encourage à lire également, mais ils sont plus avancés que le pipeline que je vais concevoir.
Cette approche est très efficace pour optimiser le calcul des recommandations et éviter les minima locaux dans le jeu de données.
Donc pour construire ce processus, nous devons construire un bon récupérateur de candidats, et Surprise avec les algorithmes utilisant des mesures de similarité (comme les modèles KNN) sont de bons candidats pour faire cette partie. Il y a le gist de code.
Il est très simple d’extraire les plus proches voisins d’un utilisateur ou d’un article à partir d’un modèle basé sur les algorithmes. Pour illustrer cela, j’ai utilisé le KNN articles d’avant pour obtenir les cinq articles les plus proches des contenus suivants.
- Le jeu Uncharted 2
- L’émission de télévision Wandavision
- Le film the dark knight
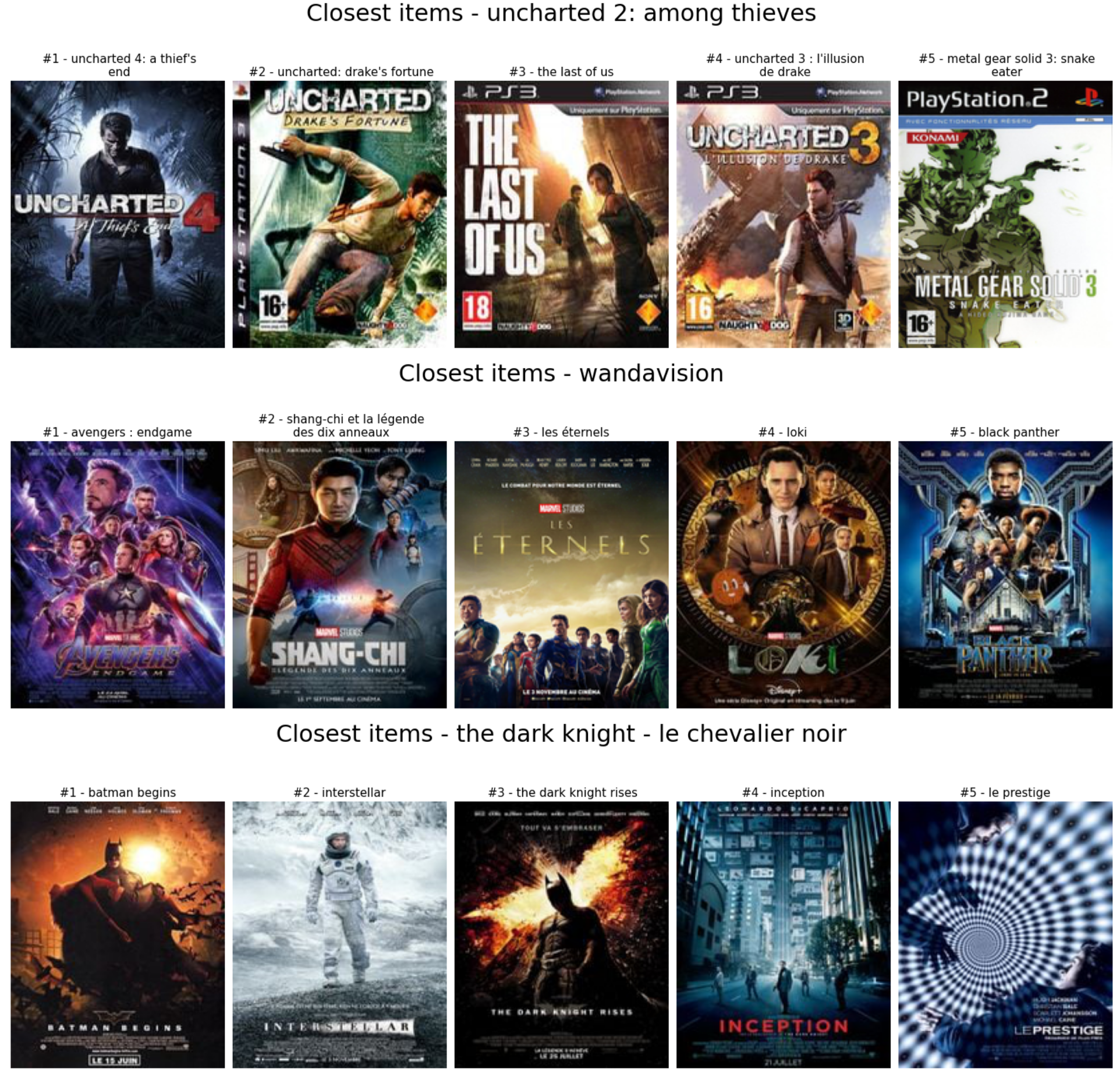
Comme nous pouvons le voir, l’association des articles les plus proches est assez efficace en :
- Associé à Uncharted 2, les jeux de la saga Uncharted + metal gear solid 3 et the last of us (produits par les mêmes personnes qu’Uncharted) qui étaient des jeux exclusifs pour la PlayStation
- Wandavision est lié aux sorties récentes de l’univers cinématographique Marvel (film ou émission de télévision)
- The dark knight est associé à la trilogie Batman de Nolan de Nolan plus quelques autres films de Christopher Nolan
Avec ce récupérateur, j’ai conçu le système de recommandation suivant.
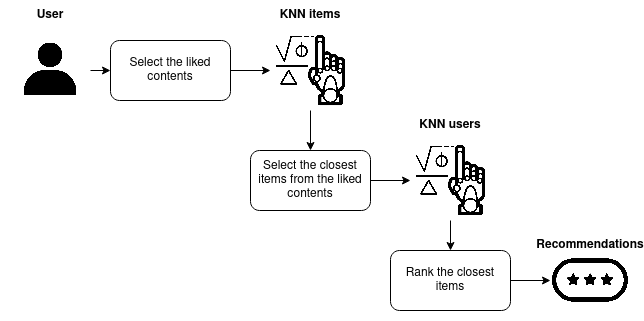
Le flux est :
- Un récupérateur qui sélectionnera les dix articles les plus proches des contenus aimés avec une note supérieure à 5) par un utilisateur (sélection de nos candidats)
- Un classeur: Évaluer le candidat pour l’utilisateur et sélectionner le meilleur comme recommandation
Il y a le gist pour le calcul.
Il y a la sortie du système de recommandation sur les archétypes.
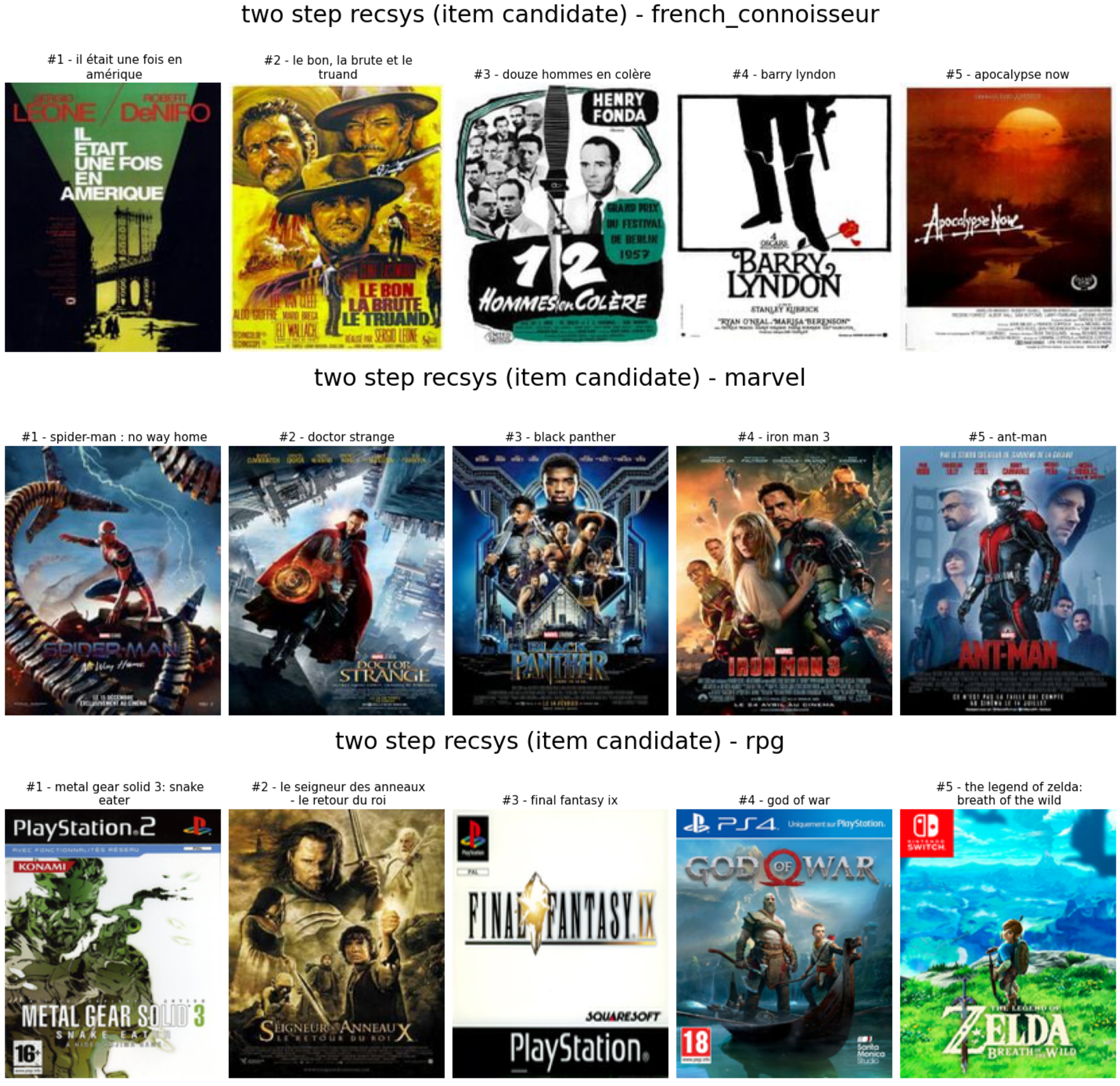
Comme nous pouvons le voir :
- Pour le connaisseur français: pas trop de films français, mais il y a beaucoup de films classiques anciens de la même période des divers comme de la persona
- Pour marvel: sélection de films marvel, bon travail
- Pour l’amateur de RPG: mitigé, je dirais bon appel pour le seigneur des anneaux et final fantasy IX, je pense, et il y a aussi de bons jeux vidéo
Globalement les résultats ne sont pas si mauvais pour ce dernier système de recommandation, mais je pense que mettre plus d’efforts dans l’exploration du modèle pourrait également apporter plus de valeur.
Conclusion
Dans l’ensemble de cette expérimentation, j’ai aimé travailler avec le package Surprise, facile à utiliser extensif en termes d’algorithmes et d’outils pour l’entraînement. Il y a aussi un composant précision que je n’ai pas utilisé mais qui peut être utilisé assez rapidement. Je recommande vivement ce package à tous ceux qui travaillent dans le domaine du système de recommandation.
Le système de recommandation à deux étapes est un domaine du système de recommandation dans lequel j’aimerais creuser davantage parce que je l’ai trouvé efficace et il semble super adapté pour ce jeu de données avec beaucoup de contenu à prédire.
Références
- Surprise — Package Python scikit pour les systèmes de recommandation — surpriselib.com
- Documentation Surprise trainset — documentation
- Package d’algorithmes de prédiction Surprise — documentation
- Surprise GitHub — références des algorithmes — GitHub
- Surprise algorithme aléatoire — NormalPredictor — documentation
- Article de Koren — Techniques de factorisation matricielle — courses.ischool.berkeley.edu
- Documentation factorisation matricielle Surprise — documentation
- SVD pour les systèmes de recommandation — Carleton College — cs.carleton.edu
- Implémentation SVD de Simon Funk — sifter.org
- The Why and How of Nonnegative Matrix Factorization — arXiv
- Stability of Topic Modeling via Matrix Factorization — arXiv
- Documentation KNN Surprise — documentation
- Article Slope One — arXiv
- Article Co-clustering — citeseerx.ist.psu.edu
- Documentation sélection de modèles Surprise — documentation
- Surprise LeaveOneOut — documentation
- Exemples GitHub Surprise — GitHub
- Modèle NMF Surprise — documentation
- Surprise KNNBaseline — documentation
- RMSE — Wikipedia — Wikipedia
- hyperopt — hyperopt.github.io
- mlflow — mlflow.org
- Surprise ConstantScorer — documentation
- Eugene Yan — eugeneyan.com
- Documentation Surprise get_neighbors — documentation
- Documentation Surprise accuracy — documentation